RedAmber

![]()

A dataframe library for Rubyists.


Overview
-
RedAmber is a dataframe library written in ruby. It uses columnar memory format based on Apache Arrow.
-
Our goal is to manipulate data frames in a Ruby-like writing style using blocks and collections.
-
You can easily try RedAmber with Dev Container. See RedAmber Dev Container.
-
We have rich document with many examples and Jupyter Notebook with 127 operation examples. See RedAmber Dev Container.
Requirements
Ruby
Supported Ruby version is >= 3.0.
Required libraries
plugin "rubygems-requirements-system" # Requires system packages automatically.
gem 'red-arrow', '>= 12.0.0' # Requires Apache Arrow (see installation below).
gem 'red-arrow-numo-narray' # Optional, recommended if you use inputs from Numo::NArray,
# or use random sampling feature.
gem 'red-parquet', '>= 12.0.0' # Optional, if you use IO from/to parquet.
gem 'red-datasets-arrow' # Optional, if you use Red Datasets.
gem 'red-arrow-activerecord' # Optional, if you use Active Record.
gem 'rover-df' # Optional, if you use IO from/to Rover::DataFrame.
Installation
You need to install the following libraries. You can automate it by enabling rubygems-requirements-system. If you want to install these libraries manually, see Apache Arrow install document.
-
Apache Arrow (>= 12.0.0)
-
Apache Arrow GLib (>= 12.0.0)
-
Apache Parquet GLib (>= 12.0.0) # If you use IO from/to parquet
If you want to install RedAmber and related gems by Bundler, you can add the followings to your Gemfile. And then execute bundle install.
plugin "rubygems-requirements-system"
gem 'red-arrow', '>= 12.0.0'
gem 'red_amber'
gem 'red-arrow-numo-narray' # Optional, recommended if you use inputs from Numo::NArray
# or use random sampling feature.
gem 'red-parquet', '>= 12.0.0' # Optional, if you use IO from/to parquet
gem 'red-datasets-arrow' # Optional, recommended if you use Red Datasets
gem 'red-arrow-activerecord' # Optional, if you use Active Record
gem 'rover-df' # Optional, if you use IO from/to Rover::DataFrame.
If you want to install RedAmber by RubyGems, you can use the following command line.
gem install rubygems-requirements-system red_amber
Development Containers
This repository supports Dev Containers. You can create a container as a full-featured development environment for RedAmber. The environment includes Ruby, Apache Arrow, RedAmber with source tree, GitHub CLI, sample datasets and Jupyter Lab with IRuby kernel. And you don’t need to worry about the change of your local environment.
.devcontainer directory in this repository includes settings of Dev Container for RedAmber. Please refer How to use Dev Containers in RedAmber to use it.
Docker image and Jupyter Notebook
(Notice: This feature may be removed in the future. Try Dev Container above.)
Docker image is available from docker folder. See readme for instruction. Integrated Jypyter notebook is in docker/notebook folder.
You can try the contents of this README interactively by Binder. ![]()
RubyData Docker Stacks is available as a ready-to-run Docker image containing Jupyter and useful data tools as well as RedAmber (Thanks to Kenta Murata).
Comparison of DataFrames
Comparison of basic features of RedAmber with Python pandas, R Tidyverse and Julia Dataframes is in DataFrame_Comparison.md (Thanks to Benson Muite).
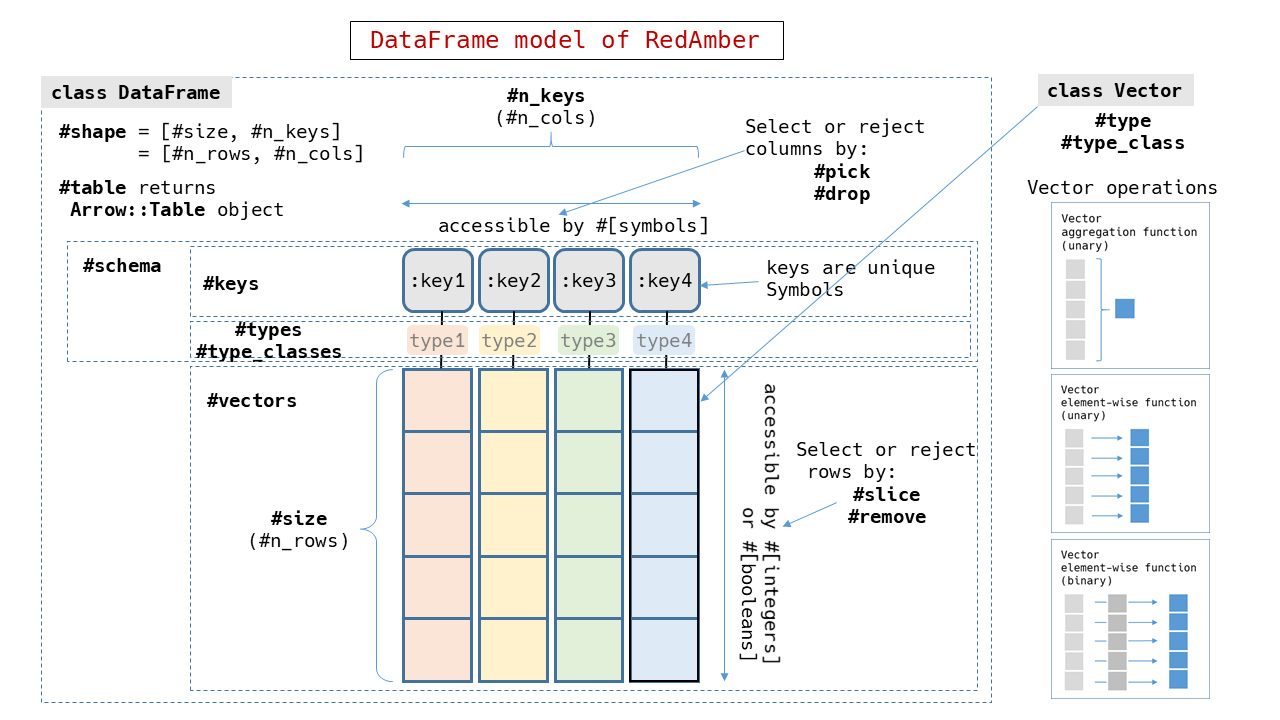
Data frame in RedAmber
Class RedAmber::DataFrame represents a set of data in 2D-shape. Its entity is a Red Arrow’s Table object.
Let’s load the library and try some examples.
require 'red_amber' # require 'red-amber' is also OK.
include RedAmber
Example: diamonds dataset
First do (if you do not installed) gem install red-datasets-arrow then
require 'datasets-arrow' # to load sample data
dataset = Datasets::Diamonds.new
diamonds = DataFrame.new(dataset) # before v0.2.3, should be `dataset.to_arrow`
# =>
#<RedAmber::DataFrame : 53940 x 10 Vectors, 0x000000000000f668>
carat cut color clarity depth table price x ... z
<double> <string> <string> <string> <double> <double> <uint16> <double> ... <double>
0 0.23 Ideal E SI2 61.5 55.0 326 3.95 ... 2.43
1 0.21 Premium E SI1 59.8 61.0 326 3.89 ... 2.31
2 0.23 Good E VS1 56.9 65.0 327 4.05 ... 2.31
3 0.29 Premium I VS2 62.4 58.0 334 4.2 ... 2.63
4 0.31 Good J SI2 63.3 58.0 335 4.34 ... 2.75
: : : : : : : : : ... :
53937 0.7 Very Good D SI1 62.8 60.0 2757 5.66 ... 3.56
53938 0.86 Premium H SI2 61.0 58.0 2757 6.15 ... 3.74
53939 0.75 Ideal D SI2 62.2 55.0 2757 5.83 ... 3.64
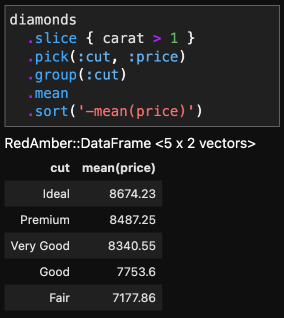
For example, we can compute mean prices per cut for the data larger than 1 carat.
df = diamonds
.slice { carat > 1 } # or use #filter instead of #slice
.group(:cut)
.mean(:price) # `pick` prior to `group` is not required if `:price` is specified here.
.sort('-mean(price)')
# =>
#<RedAmber::DataFrame : 5 x 2 Vectors, 0x000000000000f67c>
cut mean(price)
<string> <double>
0 Ideal 8674.23
1 Premium 8487.25
2 Very Good 8340.55
3 Good 7753.6
4 Fair 7177.86
Arrow data is immutable, so these methods always return new objects. Next example will rename a column and create a new column by simple calcuration.
usdjpy = 110.0 # when the yen was stronger
df.rename('mean(price)': :mean_price_USD)
.assign(:mean_price_JPY) { mean_price_USD * usdjpy }
# =>
#<RedAmber::DataFrame : 5 x 3 Vectors, 0x000000000000f71c>
cut mean_price_USD mean_price_JPY
<string> <double> <double>
0 Ideal 8674.23 954164.93
1 Premium 8487.25 933597.34
2 Very Good 8340.55 917460.37
3 Good 7753.6 852896.11
4 Fair 7177.86 789564.12
Example: starwars dataset
Next example is starwars dataset reading from the downloaded CSV file. Followed by minimum data cleaning.
uri = URI('https://vincentarelbundock.github.io/Rdatasets/csv/dplyr/starwars.csv')
starwars = DataFrame.load(uri)
starwars
.drop(0) # delete unnecessary index column
.remove { species == "NA" } # delete unnecessary rows
.group(:species) { [count(:species), mean(:height, :mass)] }
.slice { count > 1 } # or use #filter instead of slice
# =>
#<RedAmber::DataFrame : 8 x 4 Vectors, 0x000000000000f848>
species count mean(height) mean(mass)
<string> <int64> <double> <double>
0 Human 35 176.65 82.78
1 Droid 6 131.2 69.75
2 Wookiee 2 231.0 124.0
3 Gungan 3 208.67 74.0
4 Zabrak 2 173.0 80.0
5 Twi'lek 2 179.0 55.0
6 Mirialan 2 168.0 53.1
7 Kaminoan 2 221.0 88.0
See DataFrame.md for other examples and details.
Vector for 1D data object in column
Class RedAmber::Vector represents a series of data in the DataFrame.
See Vector.md for details.
Jupyter notebook
We are managing the source of Jupyter Notebook in qmd format by Quarto. You can easily create Notebooks and try it with Jupyter Lab in Dev Container.
Development
The recommended way to develop RedAmber is to use Dev Container. Please refer How to use Dev Containers in RedAmber to use it.
Otherwise run below commands after install required libraries in your local system.
git clone https://github.com/red-data-tools/red_amber.git
cd red_amber
bundle install
bundle exec rake test
We need to pass rake test in development of RedAmber, but not require to pass rake rubocop when you make a contribution. In this project we respect your preferences in code style. However, we may unify the style during merging.
Community
I will appreciate if you could help to improve this project. Here are a few ways you can help:
-
Let’s talk in the discussions.
-
Browse Q and A, how to use, tips, etc.
-
Ask questions you’re wondering about.
-
Share ideas. The idea may be promoted to issues or pull requests.
-
Fix bugs and submit pull requests
-
Write, clarify, or fix documentation
License
The gem is available as open source under the terms of the MIT License.